原文链接 https://arxiv.org/pdf/2503.07703
导言
豆包团队针对现有flux、Midjourney、SD3.5等模型对于1.模型长文本和多语言(中文)能力不足;2.不能理解中国文化 的问题,提出了seedream 2.0中英双语大模型。模型的创新性在于数据处理平台,双语言编码器以及后训练。这是一份33页的技术报告,写的非常详细。数据环节的解释非常清晰,编码器的结构和后训练环节的创新也很有亮点。尤其是后训练部分,细节多到令人感动。这篇文章让我感受到字节/豆包的底蕴,不愧是不惜血本挖人的宇宙厂,科研能力和产品能力都没得说。
数据
数据的组成包括高质量数据,分布保持数据,知识注入,以及一些针对性补充数据。高质量数据和其他模型的数据集差不多(clarity,aesthetic),分布保持是做down sampling,在保持原始数据分布情况下减少低质量数据。知识注入包括了很多高质量的中文图文数据,并且其中一部分是只有中国文化有的数据。
数据清理分三步的漏斗系统。第一步,计算quality score, structure score(水印,logo),然后用ocr去identify text。不符合的数据会被剔除;第二步,分层的进一步筛选。第三步,captioning 和 re-captioning。captioning的部分,豆包会对每一张图做 generic (长句子,短句子) 和 specialized (图片中的文字,美学,想象力)标注。
豆包还设计了一个active learning engine,先标注少量数据训练分类器,再利用分类器从无标注图像中挑选有价值的样本继续标注,形成 “标注 — 训练 — 再筛选” 的循环,逐步完善数据集。
双语言编码器
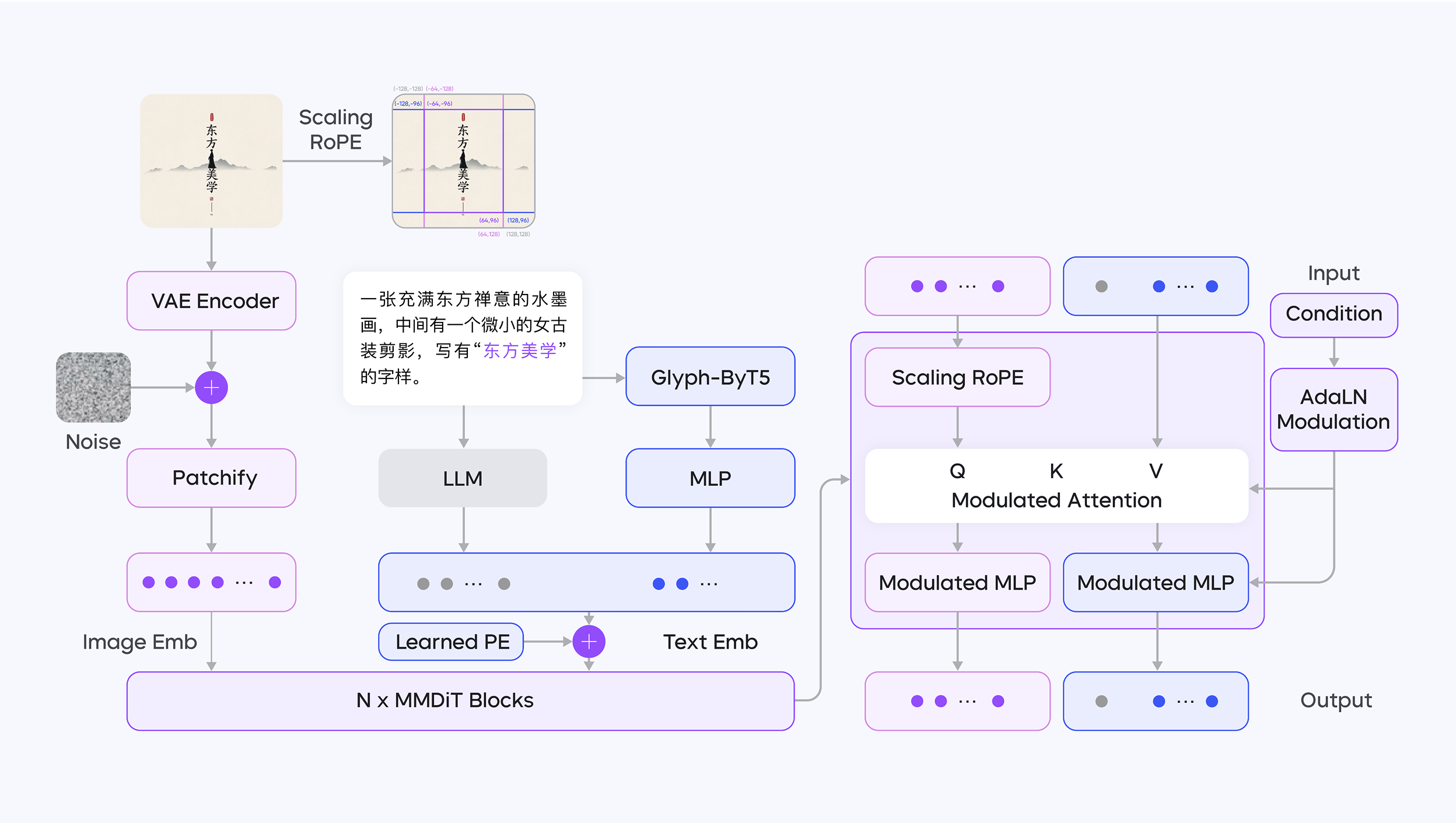
现有扩散模型一般用clip或者t5当作text encoder,因为他们的embeddings 分布比较符合扩散模型。LLM虽然能力很强,但是它的数据分布不对。为了解决这个情况,豆包收集了高质量中文数据微调了decoder only 大模型,并针对渲染文本的字形特征,同时使用 LLM(大语言模型,作为文本编码器)和 ByT5 模型进行编码。
LLM 擅长捕捉文本的整体语义,尤其对中文复杂语境(如诗词、传统民俗描述)、文化内涵有深度理解。它能从海量数据中学习中文文化特征,确保生成图像准确表达文本语义,例如在生成包含中国传统元素的图像时,精准传递文化细节。作为双语编码器,LLM 支持中英双语语义对齐,使模型在处理双语提示时,保持跨语言生成的一致性。
Glyph-Aligned ByT5专注于字符级特征处理,解决文本渲染中的布局混乱、字符重复等问题。例如,在长文本或复杂排版(如竖排中文、书法字体)中,通过字符级嵌入对齐,实现高精度的文本布局生成,确保文字排列符合视觉逻辑。对多语言字符的细节处理更精细,提升模型在不同语言文本渲染任务中的普适性,尤其在非英文文本(如中文、日文)的排版中表现更优。
Diffusion的架构是dit,运用了针对分辨率的Scaling ROPE,使得同样图片在不同尺寸下能有相似的positional encoding。
后训练
后训练分为四个阶段:
- Continue Training (CT) and Supervised fine-tuning (SFT) stages remarkably enhance the aesthetic appeal of the model;
- Human Feedback Alignment (RLHF) stage significantly improves the model’s overall performance across all aspects via self-developed reward models and feedback learning algorithms;
- Prompt Engineering (PE) further improves the performance on aesthetics and diversity by leveraging a fine-tuned LLM;
- Finally, a refiner model is developed to scale up the resolution of an output image generated from our base model, and at the same time fix some minor structural errors.
CT用了两种数据,机器从训练数据里筛选的高质量数据,以及人工选择的艺术/摄影/设计作品,按照一定的比例混合。训练的时候用了Value Mixing Control (VMix) Adapter,能更好的区分内容和美学的prompting,使得整体模型生成的图片更好看。SFT 整合了一些有标签的正样本,和一些模型生成的负样本来继续训练。
RLHF用了一个支持双语的clip作为reward mode,同时也用了 a image-text alignment RM, an aesthetic RM, and a text-rendering RM。
PE也分为两个阶段。第一个阶段是supervised llm fine-tuning,建立了一个pe模型 u -> r,u是原始的prompt,r是模型改良的prompt。训练方法一是不断改进r,使得 u能通过r生成一个好的图片。二是找高质量文本对,不断地减少r的描述来还原u。第二个阶段是rlhf,通过第一阶段的pe生成很多prompt,然后人工选取positive negative pairs来做rl。
Refiner仍然是两个阶段。第一阶段是1024分辨率scaling,第二阶段找了一些高质量texture数据做downgrade,然后用这些数据训练了一个texture模型用来guide refiner 模型。
Instruction-Based Editing
运用了自研的SeedEdit,区别于其他solution,SeedEdit用diffusion作为encoder。为了改善人脸一致性的问题,用了内部的 ID/IP 模型,以及收集了很多ID/IP在不同条件下的图片。同时,模型结构引入了perception loss(face loss)来保持人脸一致性。
模型加速
Trajectory Segmented Consistency Distillation (TSCD) methodology,把 [0,T] 的时间段分为k segment,在训练的过程中逐渐减少。Quantization上也做了微调,支持不同模型部分的量化。